The Annotated CLIP (Part-1)
Learning Transferable Visual Models From Natural Language Supervision
Multimodal
Transformers
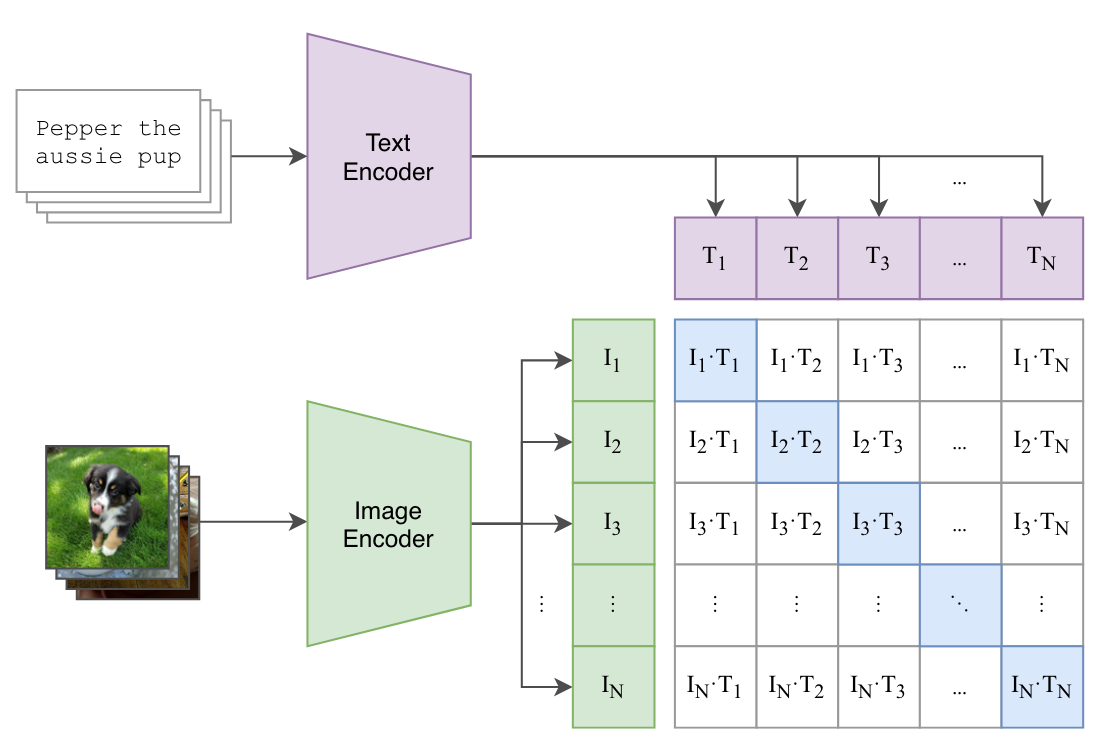
This post is part-1 of the two series blog posts on CLIP. In this blog, we present an Introduction to CLIP in an easy to digest manner. We also compare CLIP to other research papers and look at the background and inspiration behind CLIP.
No matching items